📅 Posted 2018-03-12
So lately I’ve been keeping myself busy by developing my own CMS. It’s an interesting project despite the fact that there are already so many Content Management platforms to choose from, but I’ve come up with something that works well for me. Here are my thoughts on the process.
But first! A special mention to Hugo. It is such a simple way to build fast sites. Very impressed. You should check it out.
Why do this? It’s madness building your own CMS! (aka the tl;dr)
Yes. Building a CMS will make you crazy if you aren’t crazy already. But there are also lots of reasons why this plan came about. Mostly, however, it was from talking to the DevOps people at work about how they would make a website without using common open source CMS’s running things like Wordpress, Drupal, or something else. Static HTML was the flavour of the day, so I thought about how I could come up with a solution which is delivered like a static HTML website but is also easy for clients to update. I can see people learning some Markdown but going as far as learning Git is probably out of the question.
The most obvious alternative would be to have Drupal or Wordpress locked away somewhere with the output written to a static site, but things could be a lot more fun than that!
My approach (and objectives):
- Amalgamate many approaches (Wordpress, Drupal, static, other) into a single way to build websites - providing a multi-tenant approach means it’s nice to switch between different clients
- Provide new features and make them available on all sites at once - most sites had pretty similar requirements: information pages, contact us forms, reserve an appointment forms.
- Simplify the editing process with a new, clean approach - even Wordpress can feel quite complicated these days
- Add the ability to preview content or features before publishing
- HTTPS all the things. It’s expected these days, not that hard, and it’s just a good thing
- Be able to turn off servers (EC2), databases (RDS) and anything that isn’t “serverless”, because servers are, you know, so 1997
- Maintain decent SEO performance through the use of HTTPS, highly performing static sites, decent naming of URLs and files and proper tagging (metadata and headers and so forth)
- Take advantage of any HTML or other theme which can be picked up for next to nothing
Solution Design
Time for a bit of a diagram.
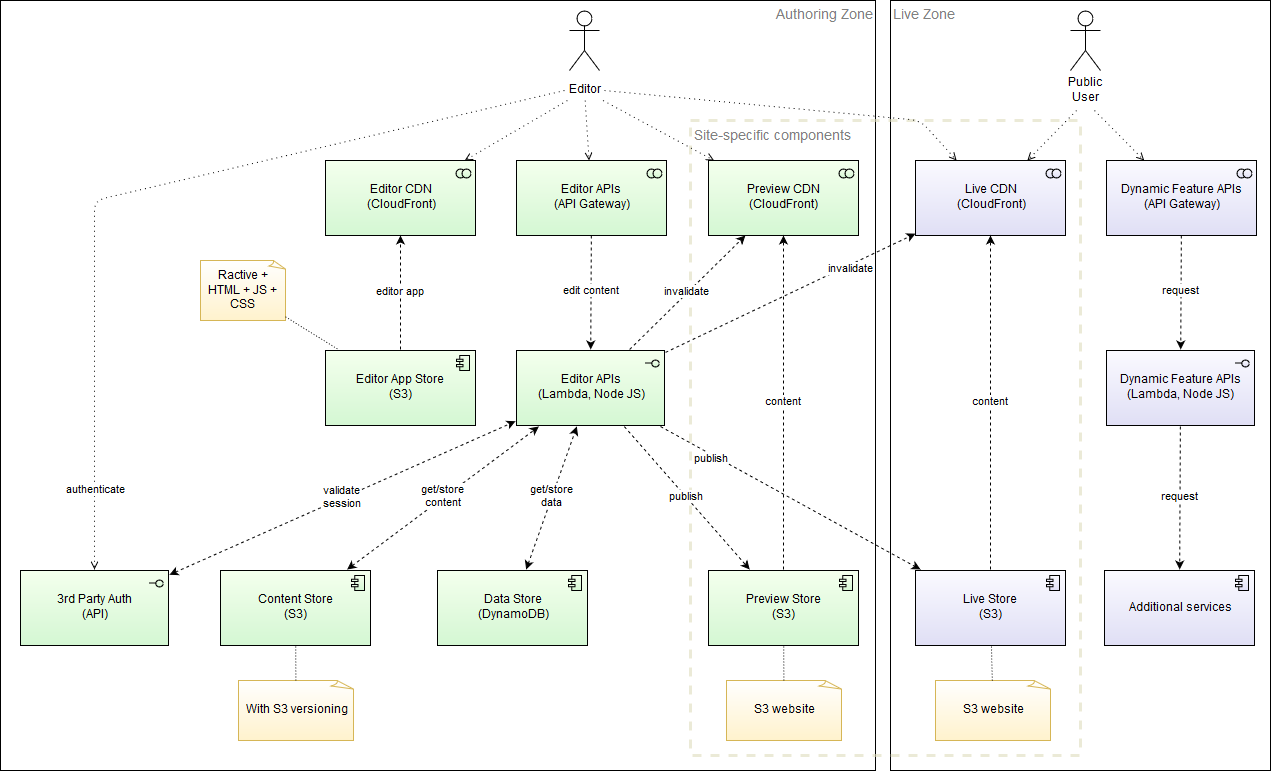
The plan was to look at what templating engines were available and work from there. Jekyll was considered early on, however Hugo came out on top as it didn’t require any dependencies to be installed to make it work. A single executable is all that is required, and it works just as well on Windows or Mac as it does in the AWS Lambda environment.
Templates would be converted into HTML chunks that Hugo understands and combined with static JS/CSS resources. This has the added advantage of buying templates in HTML format being a whole lot cheaper than Wordpress or Drupal equivalents.
All content would be authored using Markdown, because it seems quite simple and gets the job done without too much baggage. Users won’t be required to learn Markdown through tools that help mark up the content with a menu bar of formatting options. Simple and cheery. Add a bit of YAML to configure some metadata attributes and pages would be good to go.
Source files would be uploaded to S3. Versioning switched on to save those embarassing moments when something needed to be rolled back and metadata applied to record which user made the change.
The Hugo executable is deployed inside a Lambda function, running Node JS, sitting in AWS. Now, originally when the system was built, Go was not available in AWS Lambda, however since that’s now a possibility, this could change.
The publish process isn’t super complicated, but it’s basically:
- Get source files from S3 bucket
- Run Hugo with specified base URL and selected theme
- Transfer output from Hugo to preview or live S3 bucket
- Invalidate CDN cache
From that point on, ignoring utility functions like backups, Lambda functions don’t execute unless content is updated or a dynamic feature like a “Contact” form is submitted. So the server costs of running such a system are super low and are basically storage (very low) and cost of delivery via the CDN.
Talking about functions, the system is API driven, with a separate API for the editor environment from dynamic features on sites. The editor itself is essentially a static HTML website which forms API calls and lets users modify their websites. Authentication is handled by Google, because it’s easier that way for users and for me. Users are of course encouraged to use 2FA on their Google accounts.
The content editor is based on an HTML template that I bought, which is a great approach when you don’t have 1337 front-end skills (such as me), but want something to look nice and known to work across multiple browsers. It’s also quite inspirational to pick and choose all kinds of example UI elements without having to think too much about building them. Decent modern browsers like Firefox, Chrome, Edge and Safari are supported. Internet Explorer, no way.
What else is there? DynamoDB stores some persistent information that would normally go in a traditional database, mainly to keep the serverless thing happening. AWS API Gateway provides a way to call all of the AWS Lambda functions (which are written in Node JS), and of course other essential AWS services like Route 53 are involved too. Some customers have DNS hosting at their end so that’s left untouched in that scenario. There is quite a lot of CloudFront going on plus the freebie SSL/TLS certs from AWS make the whole thing a bit nicer.
The migration process
Twelve sites are now powered by this AWS-powered Hugo Serverless CMS (including this one). They came from a variety of sources and some took longer than others to convert over, but once I had the process started I was on a bit of a roll with chopping up the HTML into templates (the most time consuming part) or creating Markdown files (super easy). Some of the sites were Drupal, some Wordpress and others Jekyll.
The process goes a bit like this:
- Clone a base website structure and configure basic settings like name, URL, analytics code and so forth
- Commence building a theme by saving all static assets like images, Javascript, CSS and font files from the existing site (or from a purchased theme)
- Carve up the HTML into base templates and smaller “partials” to be reused and included - this process is actually easier than I thought it would be and the result is quite a neat set of small, maintainable templates - this step also includes testing and adjusting code or adding missing static resources like js, css, fonts or images
- Optionally, create some “shortcodes” which are smaller bits of HTML that can be referenced in content, to make layout a bit nicer so pages don’t look quite so plain
- Convert all existing content into Markdown files - tried some automated scripts but in the end it was easier to copy and paste since there aren’t that many pages to migrate
- Create all of the AWS infrastructure (usually a couple of S3 buckets, some IAM permissions and a couple of CloudFront distributions) - currently not scripted but wouldn’t be hard, it’s just the investment isn’t worth it for a handful of sites at this stage (also request + approve TLS certificates)
- Upload to S3 and click the GO button - magic happens here! Actually, it’s usually pretty successful on first run
- Mess around with some DNS settings to create some aliases that point at the preview and live CloudFront distributions
- Kick back and watch the traffic roll in
The great thing about this process is that it is super quick to make changes with Hugo running on your local machine, then you can deploy to the web and it’s very reliable in getting the same result. The dev cycle with Hugo running and picking up changes is quite nice, to the point where you don’t even need to press F5 to reload the page in your browser.
So what does it look like?
Here is one of many screens available, showing the SimpleMDE Markdown editor, with some niceness coming from the purchased theme “ProUI” by Pixelcave. Editing this blog entry is shown in the image below.
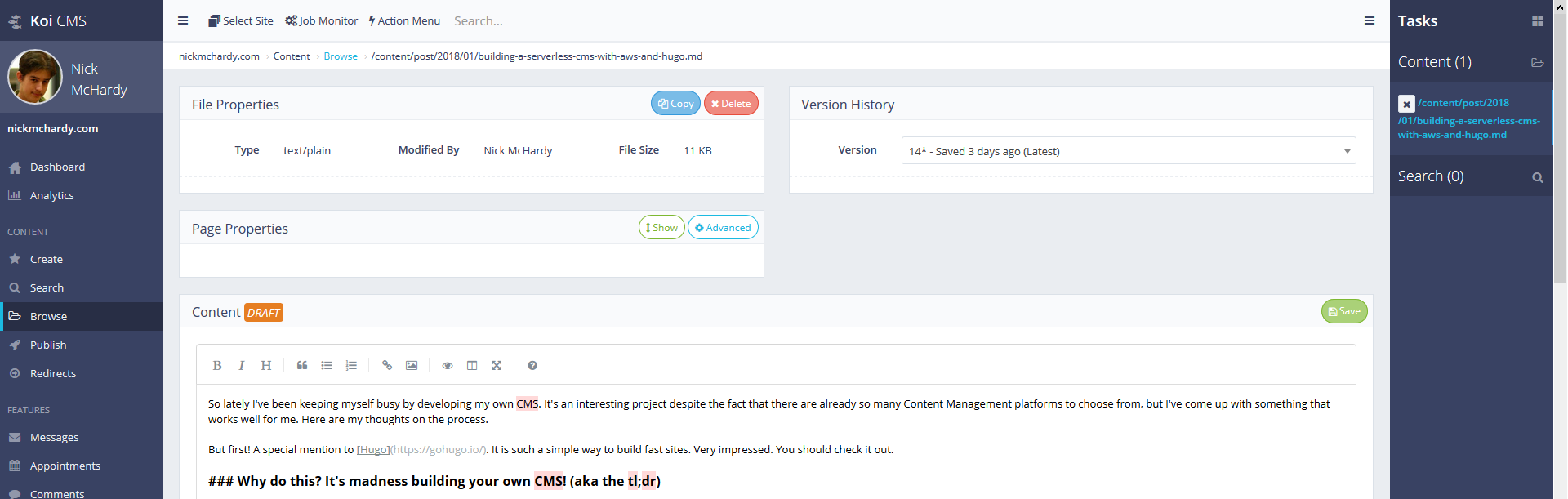
Naturally, this still needs a bit of work - for example, the File Properties section is too techie and it’s generally a bit of an over-engineered file editor. But I think the focus is always to make it work before making it amazing.
Let’s talk scaling for a moment
Overall, the solution scales pretty well. Lambda performance is fairly predictable especially since it’s only used when modifying content. Actually delivering content to the audience with S3/Cloudfront is also quite good.
DynamoDB is OK but not great. Although recently AWS has corrected it with a bit of elastic capacity for reads and writes, which is welcome. You could say it’s a lot more “dynamo” now.
Hugo is quite unscalable and is probably one of the biggest weaknesses for scalability. At the moment, the process to publish is monolithic: You have to publish every page every time. Small sites with about 50 pages publish in a couple of seconds, which is quite rad. Larger sites with 4,000 pages take about 40 seconds, or about 100 pages per second. It’s actually quite good considering, however it would be nice to have a model where the processing of Hugo could be split into different Lambda invocations for parallel publishing.
Wrap Up Thoughts
There are still a few niggling issues which aren’t fantastic. Here’s some of my thoughts:
- When previewing changes, this works really well for individual changes. But you can’t pick and choose something to deploy if you have multiple changes sitting in preview at once. They all go to ’live’ immediately.
- The same goes for if you make changes and then click on the “live” publish button - it goes straight to the live website without hitting preview first. It’s an MVP, right?!
- Being able to select Hugo “shortcodes” and let the user configure them in a nice way is not possible yet. So when adding rich content, it’s basically knowledge of the shortcodes available, or throwing in some HTML which isn’t great.
- I’ve been using Ractive as the JS framework in the editor and it’s OK but seems a little dated these days and isn’t great when working with decorators like Select2 - it works, but it feels a bit dirty
- There are stacks of new features I’d like to put into the editor over time, but they will have to wait for another time. Some examples are better integration with Google Analytics or a convenient way to edit taxonomies
- AWS Lambda now supports Go natively - maybe port Hugo to a Lambda-friendly version without having to wrap the shebang in Node JS?
Like this post? Subscribe to my RSS Feed ![]() or
or ![]() Buy me a coffee
Buy me a coffee
Comments are closed