📅 Posted 2018-04-04
So it turns out using S3 as a data store and pseudo-query engine isn’t all that crash hot. Sure, it “works” with about 200 items but for sites pushing thousands of files of content, you can quickly see it’s not ideal to pull down large chunks of file lists. It’s also pretty poor at some of the more rich functionality like listing some header information or metadata about each file which would require additional S3 calls for each file.
A few aims, in no particular order:
- It must be easy to use and familiar for CMS users
- It must perform “fast enough” that it doesn’t frustrate users
- It must be serverless (the experiment continues)
- It must provide richer information about each file in the content store including header information (such as page title), draft status, and other file metadata such as who last modified it, etc.
- It must power the search feature so users can find specific files based on a query
To meet #1, I took a “browse the folders” route which looks fairly similar to Windows Explorer. Folders are nice attractive icons at the top and files are listed in table format below. Here’s a quick screenshot showing what CMS users can see:
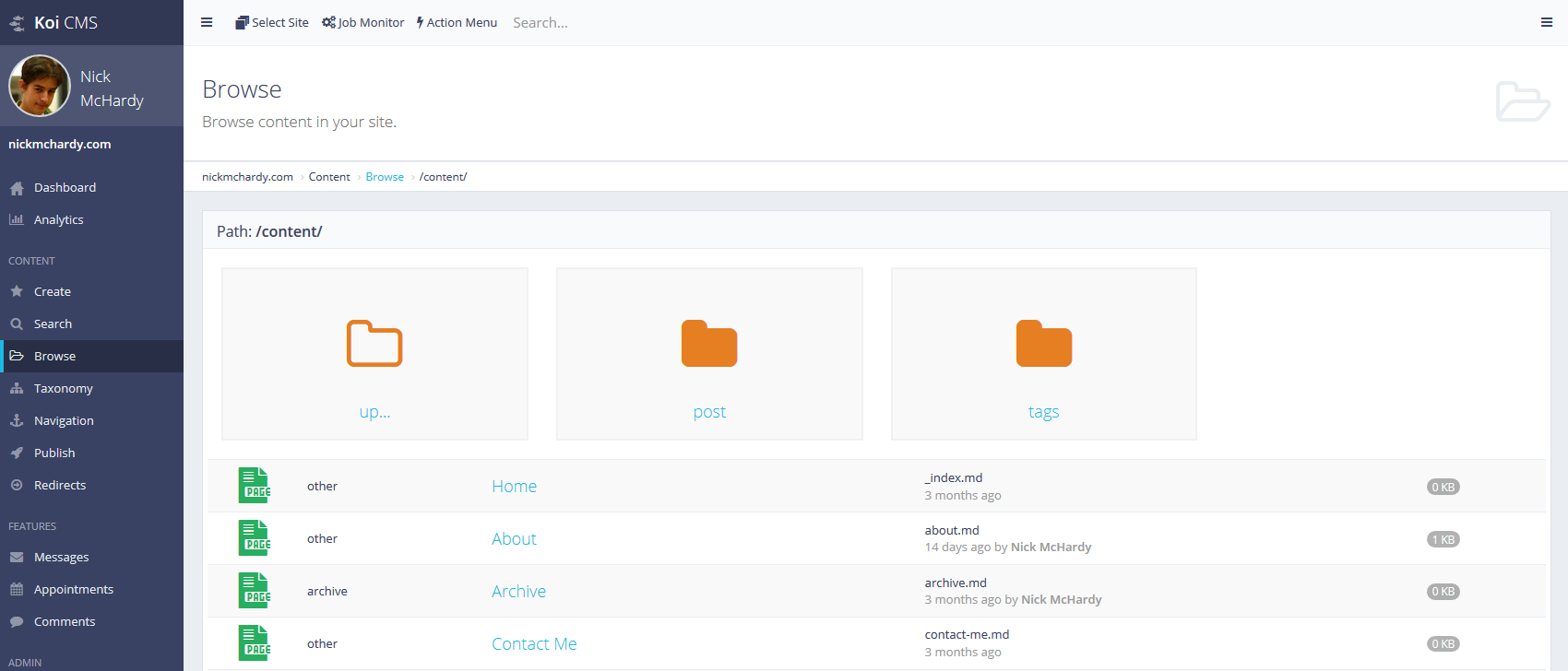
For #2 and #3, I built up 2 new caches in DynamoDB which serve the following purposes:
- An object cache which stores lots of information about each object including expanding header and metadata properties
- A folder cache which stores all “folders” (S3 of course has no folders but we create fake folders purely for ease of navigation)
At a pinch, you could probably get away without having a separate cache for folders, but I think this is a cleaner approach with more room for growth in the future.
Other options considered were: an RDS instance, Elasticsearch, ElastiCache, and even a giant “index” JSON file in S3. Some of these options could still be a possibility in the future. Given the isolation of only 3 API calls requiring access to the cache, the move to a different technology to power it wouldn’t be too bad.
The load on DynamoDB when reading is pretty heavy when compared to all other existing tables, and it therefore sucks up quite a lot of capacity for these 2 new tables. The good news is it fits into my existing reserved capacity, so there is no new cost for these tables.
One of the main reasons why the load is high is because queries which use the “CONTAINS” function in DynamoDB queries will force the query to turn into a SCAN operation, which is akin to full table scans of old. This is despite using the “query” endpoint for DynamoDB. The use-case for this is to allow CMS users to search for files of content by name, title or path. I know, I can hear what you’re saying, I shouldn’t be using DynamoDB for searching and I agree. But for now, as it performs OK and doesn’t require any additional investment in infrastructure, so it’s acceptable.
Integration with API calls to refresh the cache is made on a number of different scenarios within the CMS, including:
- Creation of new pages or posts
- Upload of images or other media assets
- Renaming of files
- Saving of files
- Copying files
- Deleting files
All of these scenarios require partial updates of the cache, so an optional “prefix” parameter is available to refresh only portions of cache. Complete cache rebuilds are also possible if the prefix parameter is omitted.
The interesting thing is trying to keep S3 and the cache nicely in sync. It’s important this is done in a timely manner in case the user searches or browses for some content they just created. Instant feedback is important here. “Losing” files because they are not found in cache is not acceptable! Of course, the files are never lost, they are just hidden by not being present in the cache at the time of query.
Here is how the architecture now stands with the two caches in place:
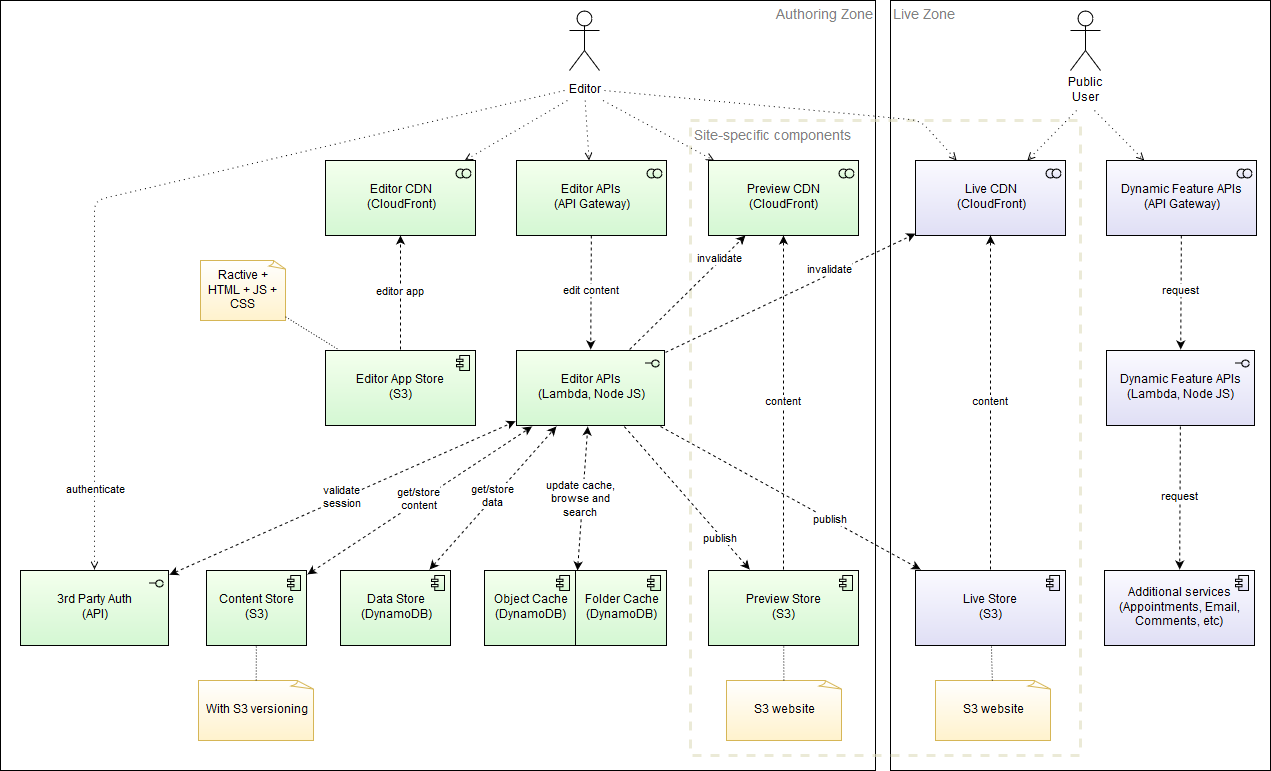
It’s not a huge change from before but it now means I can deliver a file browser, a search feature, better performance and more features than using plain S3.
Lastly, here’s an example of the output of the search:
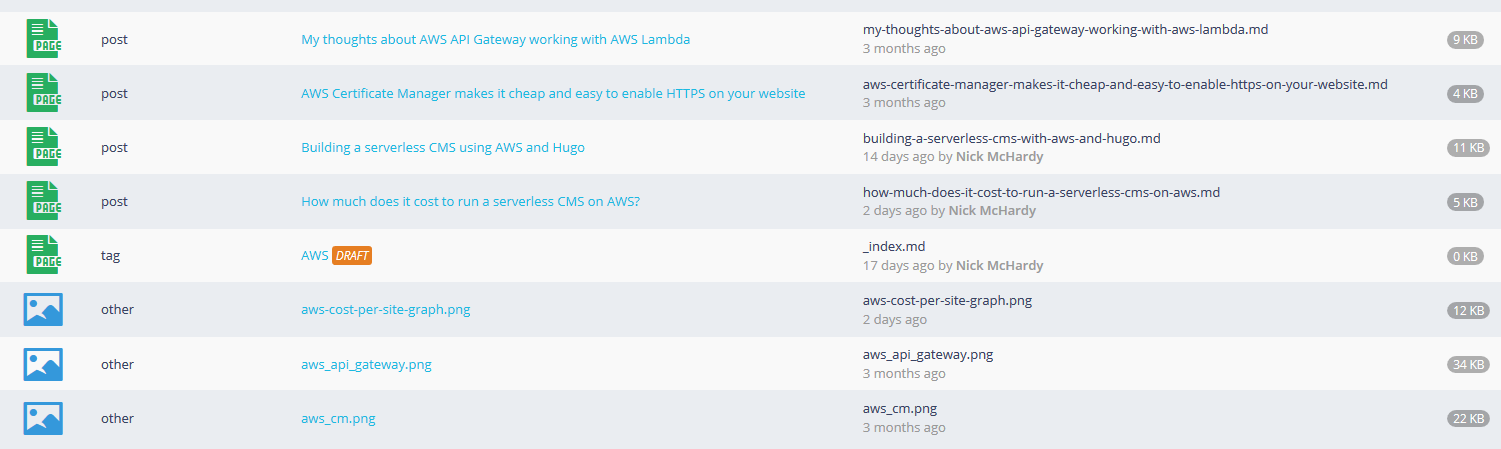
This has a few nicer features which weren’t possible before, including:
- Being able to search on page titles
- Displaying the page title in search results
- Display who edited the file last
- Tagging items which are DRAFT
- Identifying which files are of certain types, such as taxonomy terms, pages, posts or other custom types
So there you have it, one step closer to being a fully functioning Serverless CMS. It’s actually pretty close to a basic Wordpress install now, with a couple of richer features thrown in for sites that need them and multi tenant capabilities for users who have access to multiple sites from a single UI.
Like this post? Subscribe to my RSS Feed ![]() or
or ![]() Buy me a coffee
Buy me a coffee
Comments are closed