📅 Posted 2019-01-23
The tl;dr
Using AWS Polly to read my articles and generate audio “podcasts” results in an average listening experience. It works and it’s easy, but I wouldn’t want to use it as my primary way to generate articles. Want to hear why? Read on…
(Those wishing to sample the results without reading the gory details can scroll to the end)
The concept of Generating Podcasts using Amazon Polly
Rather than having to painstakingly record and edit all of my articles with a proper mic, what if I use something like Amazon’s Polly on AWS to do the heavy lifting for me?
It’s certainly a feature I could add to my CMS, Koi CMS, since publishing podcasts isn’t all that different from publishing text-based content on zee old internet. It’s also a valid extension to the “serverless” architecture: I can call Amazon Polly on demand for when I need some text converted to audio, without having to worry about spinning up and manging servers or even training a machine-learning model to understand text.
I played a few samples which resulted in some early feedback such as:
It’s Nick, but it’s not Nick. It’s Robot Nick reading!
Robotnik sounds all very Sonic the Hedgehog, to me. Anyways…
Never fear, a diagram is here
I’m a sucker for some boxes and lines, so here’s a drawing to illustrate how I was going to “bolt on” such a feature to Koi CMS.
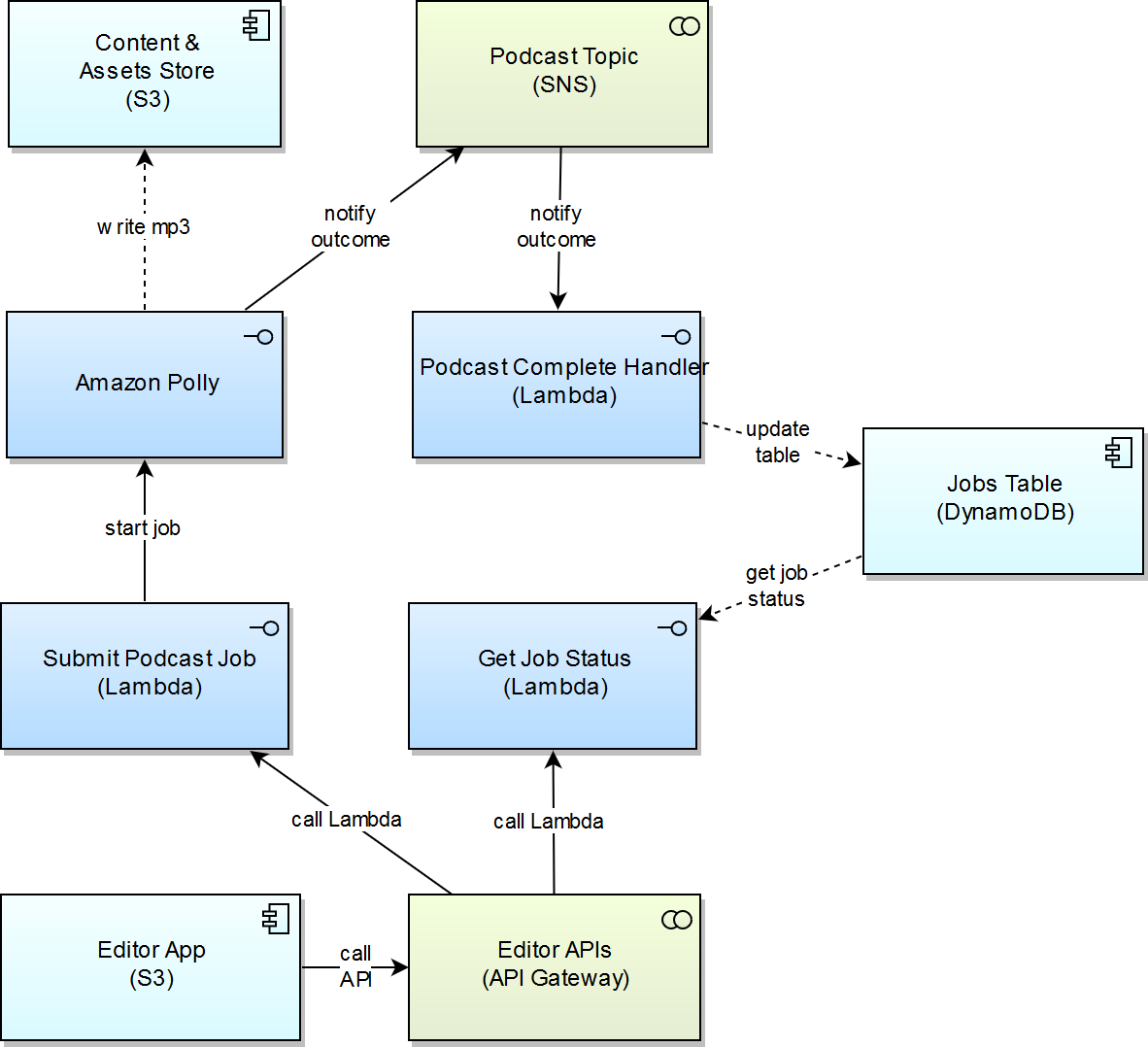
In total, I had to create a few new components:
- A Lambda function to start the podcast creation process
- An SNS topic to be notified when the podcast generation process is complete
- A Lambda function to handle the completion of the job, which would subscribe to the SNS topic
- 1 new route in API Gateway, with associated CORS setup, to allow users to request a new podcast job
In addition, I had to refactor a few different functions and screens to make it possible. Overall, about 400 lines of code was changed or added to complete this feature. No data schemas were harmed in the production of this feature.
The next few steps deal with how the user can approach generating a new podcast.
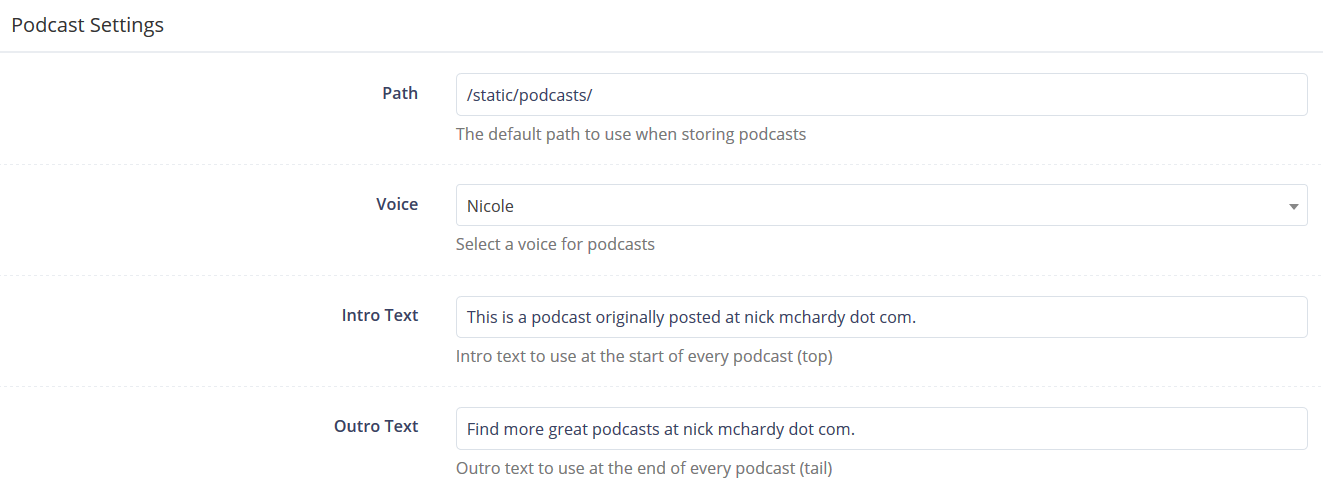
Step 1: Configure the site
First up, I figured it would be good to top ’n’ tail each “podcast”, so that you could have an informative intro and outro for each piece of content. Then I added a simple setting for where to store the generated podcasts and finally a dropdown list featuring all the different kinds of voices that Amazon Polly provides.
In the end I only trialled the two Aussie voices: Russell and Nicole, which are amusingly named after some famous Aussies. That’s my theory anyway (I have no basis on which to justify this). And yes I realise that Russell Crowe was born in New Zealand and Nicole Kidman was born in Hawaii. Scandalous!
Step 2: Find an article to convert
I added a button to kick off a conversion job. The key here is that the article should be saved first, so that the audio content matches the text content. In hindsight, I should’ve made UX more of a priority: but I’m subscribing to the “make it work before making it better/great/fast” philosophy.
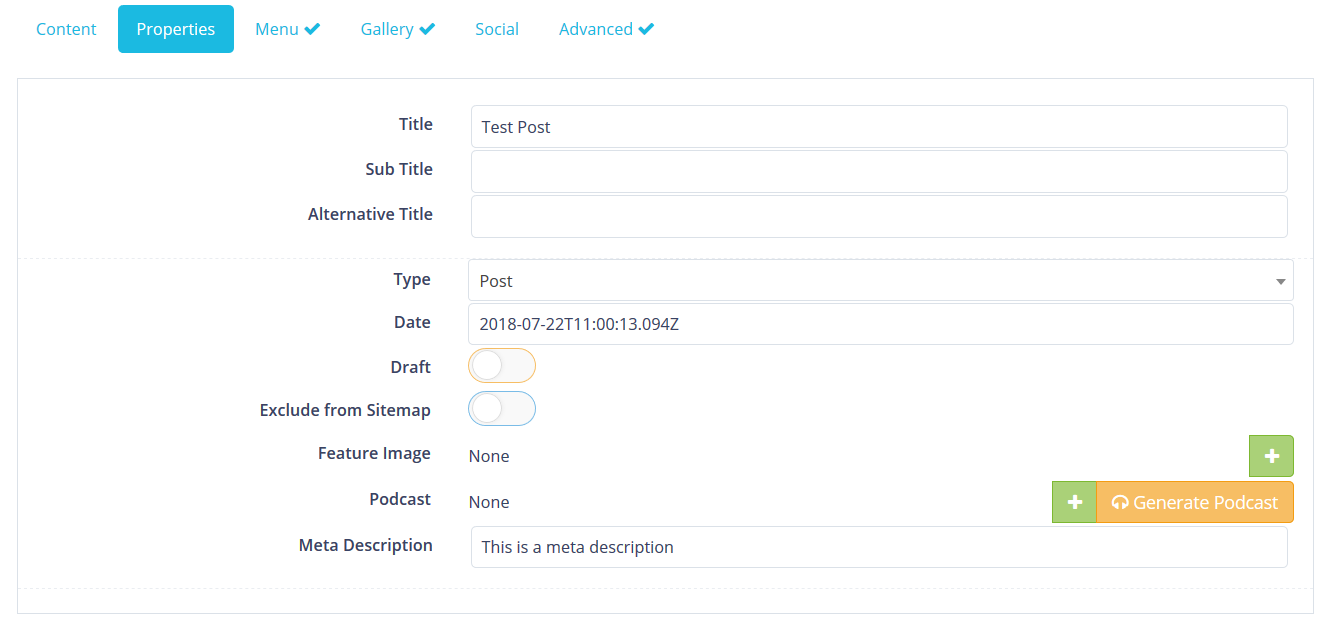
Click the big orangey-yellow button.
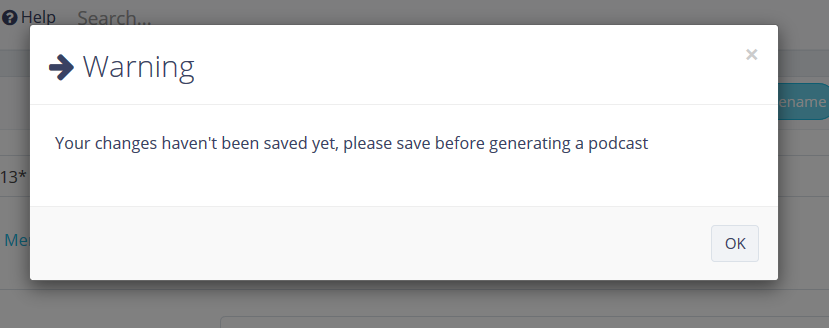
Oops! Not saved yet… I decided it would be good to sync up the text with the audio, so there was no discrepancy. Still possible, of course, but this should reduce the gap. It’s easily fixed with a simple CTRL+S.
…. and we’re on our way.
Step 3: Wait for the job to complete
I already had a job monitoring system for publishing websites to preview or live environments, so it felt quite natural to expand this to also cater for Amazon Polly jobs. The thing is, if you want to convert more than 6,000 characters then you can’t use the SynthesizeSpeech function, you have to submit an async job with StartSpeechSynthesisTask. This works better than expected, with a simple notification being sent to a nominated SNS topic upon completion (or failure).
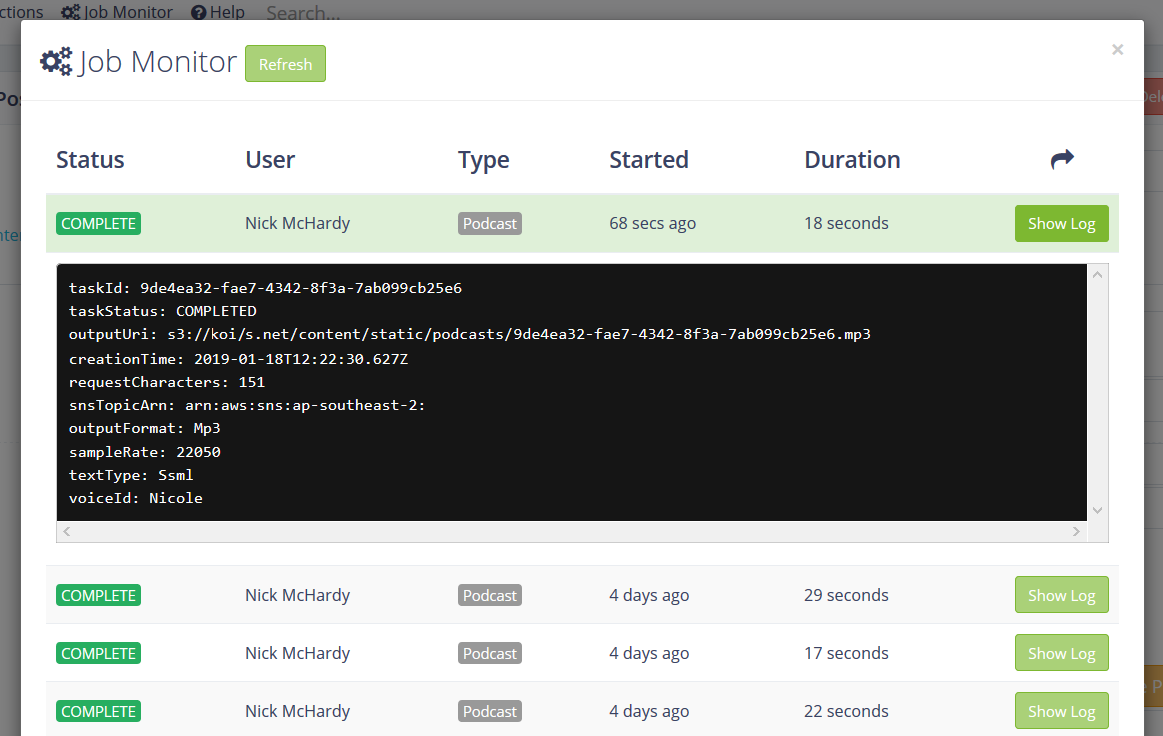
A technical log was added to keep track of details, in the event of a failure (I haven’t seen one yet).
Step 4: Attach to the article
Now we attach the generated mp3 file to the article in question. This is quite simple and yet powerful because even if you don’t use Amazon Polly, you can still record your own podcast and attach any podcast-worthy audio file.

At some stage in the future, I’m sure this step could be automated. But at this point in time, a quick manual step will be fine.
Step 5: Publish the site!
Here we go, publish away! I think the intriguing fact is that publishing the whole site is faster than Polly generating one podcast. Shows just how immensely fast Hugo is (Hugo is running on a 2048MB Lambda instance which appears to be the sweet spot of publishing time vs cost - a good topic for another article).
The results
Well here you go, have a listen. I’ve converted this very article for you to compare.
Russell reads my article
Nicole reads my article
Some improvements
Along the way, I found I had to do some minor improvements to get an acceptable result.
Plain Text vs SSML
So I started with simply concatenating the intro, post title, post body and outro all into a large, hideous text string. The results were rushed and even worse than what you hear above. I then switched to the xml-based SSML format which allowed me to add slight pauses between each stitched segment of text. It was much more natural sounding, this way. The pauses are 0.7 seconds in duration and aren’t configurable (at this stage) in Koi CMS.
Markdown noise
As most content in the CMS is authored using Markdown, I had to remove some Markdown markup along the way, otherwise poor Polly was announcing all of the hashes, URL components and image links. Actually, it does a pretty good job of reading out URLs, however they aren’t very appropriate in this context. An example would be nickmchardy.com, which is spoken as “nick mchardy dot com” without any effort on my part. So that gets a tick in my book.
More configuration options
This is really on my side, but I’d like to be able to:
- Sample the voice types more easily, to make it nicer to select an appropriate voice
- Configure how Koi reads out the article title and date, as this is currently fixed in a single format
- Attach the podcast file to the article automatically (in the front matter), saving a few clicks (it’s an async process so this would require a bit more monkeying around)
- Auto generate podcasts upon publish (if not already generated) - would also require attachment to articles
What I like about Amazon Polly
There’s a few things which are pretty cool with Amazon Polly:
- It’s dead simple to use, if you’ve ever integrated any other AWS service before
- The results are good considering you don’t need to be an expect in speech, ML or language
- The pricing is reasonable: assuming you’re outside of the free-tier, Amazon Polly is priced at US$4.00 per 1 million characters for speech or Speech Marks requests. An article which takes 10 minutes to read has about 25,000 characters and should cost about 10 seconds to convert to speech
- The speed is OK: not exactly instant, but definitely faster than real-time
- Using the SSML format means you can tweak the way Amazon Polly paces and speaks
- It does a decent job at reading out URLs and host names
What’s next?
Making my shiny new “podcast” public. To do this, I’d need a template in Hugo which generates a valid podcast XML file, which can then be shared with all the various podcasting aggregators like iTunes and Google Podcasts. This file is pretty similar to an RSS feed, however I’d limit the results to only the posts which have a value in the “podcast” property in the front matter. I think I’ll hold off on doing this as the results are less than ideal.
Some other features which are possible could be an “auto” publishing feature whereby posts generate podcasts automatically (if changed since last publish) by calling Polly. After playing with Amazon Polly for a bit, I don’t think I’ll be pursuing this enhancement as a priority.
I haven’t tried any of the Custom Lexicon features at this stage.
Now I can appreciate what sight impaired users have to contend with when they use screen readers all day. I wonder if it’s practical to inject SSML tags into websites to make the text-to-speech engine generate more natural speech? Just a thought.
Some additional information which you may find useful
Like this post? Subscribe to my RSS Feed ![]() or
or ![]() Buy me a coffee
Buy me a coffee
Comments are closed