📅 Posted 2019-03-30
It’s been a year since I initially wrote about Building a serverless CMS using AWS and Hugo and I figured it was probably a good time to provide an update on the architecture for Koi CMS, a serverless CMS. It’s progressed quite a bit over the past twelve months.
Kicking things off with a meaty diagram (click to zoom):
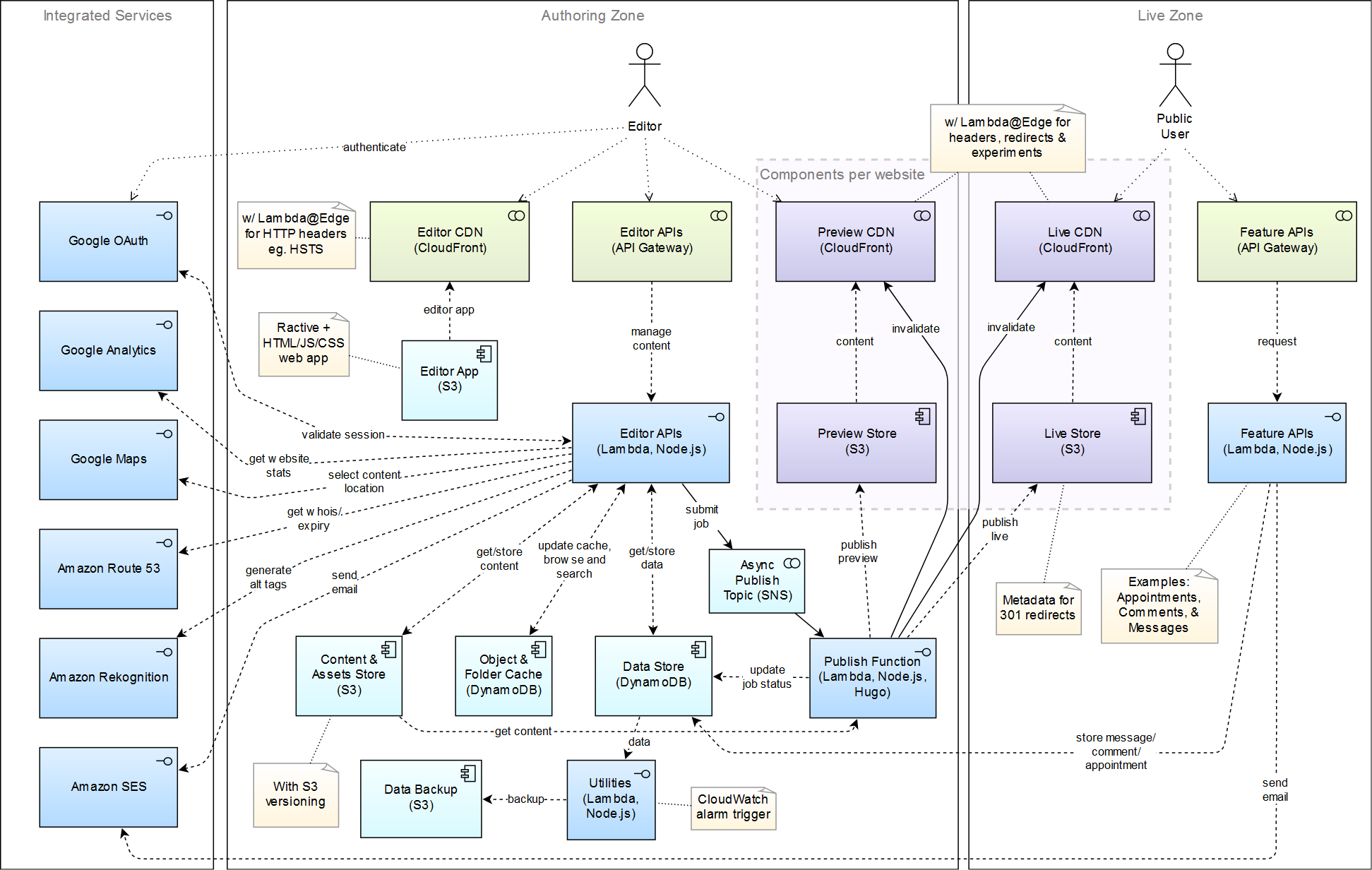
Uh yeah, it sure has grown over time. Still manageable, but certainly not as simple as it once was! Why is that? Well I added lots of…
Features
Functionality-wise, a lot of things have been added. Some things I didn’t even end up using - but I suppose it was the fun of adding a new feature which was really driving a lot of the feature development. Here’s a few highlights:
- Using Amazon Rekognition to produce better alt tags
- Using Amazon Polly to automatically generate podcasts
- Route53 integration to look up whois, domain expiry and domain privacy settings
- Google Maps integration to allow content editors to pick long/lat co-ordinates for content
- A/B Testing using experiments: my sites simply do not get enough traffic to prove with significance (in a short period of time) that one way of displaying content is better than another - but at least I could run an experiment if I wanted to
- Loads of Lambda@Edge to do security headers on all the sitez. “A” seems to be very achieveable, “A+” is a little harder. Still important, though.
- Fixing small things in the UI like enabling the forward/back browser buttons in a single page app (it’s really nice, do it)
- Finer grain security with permissions for different modules/features, mainly so I can add extra users to the CMS without having to give them full content-editing rights (also so I can manage the billing section without customers marking all their invoices as ‘paid’!)
- A list of release notes for users so they know when things have been improved/added/fixed, but it is hard to keep this non-technical for some changes
- Multi-file uploads and deletes for managing lots of files at once
- A few UI tweaks for things like sort orders, folder navigation and other handy bits and pieces
- Easy ways to insert images, link to other content and add folders full of images to galleries on pages
- A dependency/reference checker so you can work out where a particular asset (such as an image) is used (handy to know before deleting a file!)
Performance
Some performance tweaks were also made along the way, with the most significant being a “direct” to API Gateway connection from the editor. I was able to cut down on the API latency by using the standard ugly generated API Gateway endpoint, rather than using a custom domain, which seemed to add a lot of latency and go via the “CloudFront” network - which is not very useful for uncacheable POST requests.
Secondly, tokens were introduced to avoid some hits to the database on function calls. This literally halved the API latency from around 200ms to under 100ms for most operations (assuming a warm Lambda function). I could also remove many lines of code in the process. The front-end code literally didn’t need to change to make this possible, which was a win.
Oh, and about warming Lambda functions? I might get to that in the future. For now, the first user takes the hit (it’s not all terrible, but it is noticeable for me). If I had more users then I reckon this would be less of a problem.
Publishing Performance (with Hugo)
Taking a deeper dive into Hugo for just a moment, of course it’s still blindingly fast, however on my largest site with over 4,500 pages, the system can take up to 25 seconds to publish. That’s not bad considering everything has has to happen behind the scenes, but where is all the time spent? Here’s a sample breakdown of the “Publish” function:
<1s Get Hugo
9s Get source files from S3
6s Run Hugo
7s Upload generated files to S3
1s Invalidate CDN
<1s Cleanup
----------------------------------------
~23s TOTAL (4550 files published)
So basically, out of 23 seconds, 16 seconds is spent either fetching files from S3 or uploading them back to S3 again. Not a lot of easy options to improve this, and increasing the memory size (from my balanced base of 2GB) for each Lambda function doesn’t seem to magically offer any more network throughput or connections (assuming this is the governing factor).
One thing that made a huge difference early on in the development of the product was avoiding logging too much to CloudWatch. Initially, for development reasons, I had a log record for every file that was found, copied and stored successfully. It was good to know when building the app, but after it was working there was no need to log so much information. Disabling this level of logging shaved off about 10 seconds from the process to take it from 35 seconds down to 25 seconds, which is quite significant for removing a bit of logging.
For smaller sites, the time spent publishing is not linear either: my site is about 450 files and takes about 7 seconds to publish. It’s not bad when you think that every single file is being copied, processed, uploaded and then the cache is invalidated. It’s a bit like having to crawl the entire site, but only when content is updated.
I could optimise how the files are transferred based on detected changes (eg using etags) but I think this is a level of complication for a problem that nobody has complained about…
A Few Lessons learnt
- Don’t build features you’re never going to use. I know it’s obvious, but it’s so tempting to add something special that nobody really wants.
- Teaching non-tech-savvy content authors Markdown is really hard! But so is improving the interface so that you don’t need to teach people so much. I really need to focus on this next.
- I should’ve started out with an editor theme which was open source sharable (as opposed to being a commercial theme) so that I could open source the whole platform if I chose to (several people have asked for it to be open source).
- Linting is important (and saves some silly mistakes) but it’s a huge amount of work to retro fit it if you haven’t been super strict from the outset.
- Do log optimisation: don’t log all the payloads on the way IN and OUT of a Lambda function, particularly if they are dealing with uploading files in base 64 encoding! Traditional log levels would help here, so you can dial up the logs when you need it.
- The CMS market is hugely crowded and building a successful platform which rivals other options technically isn’t a selling point in itself.
- Git + your choice of CI/CD platform is invaluable, despite the initial learning curve. Saves so much time!
- Nobody has time to edit content on their websites.
Like this post? Subscribe to my RSS Feed ![]() or
or ![]() Buy me a coffee
Buy me a coffee
Comments are closed